Welcome to ipfs-search documentation!

This is the main documentation repository for ipfs-search.com
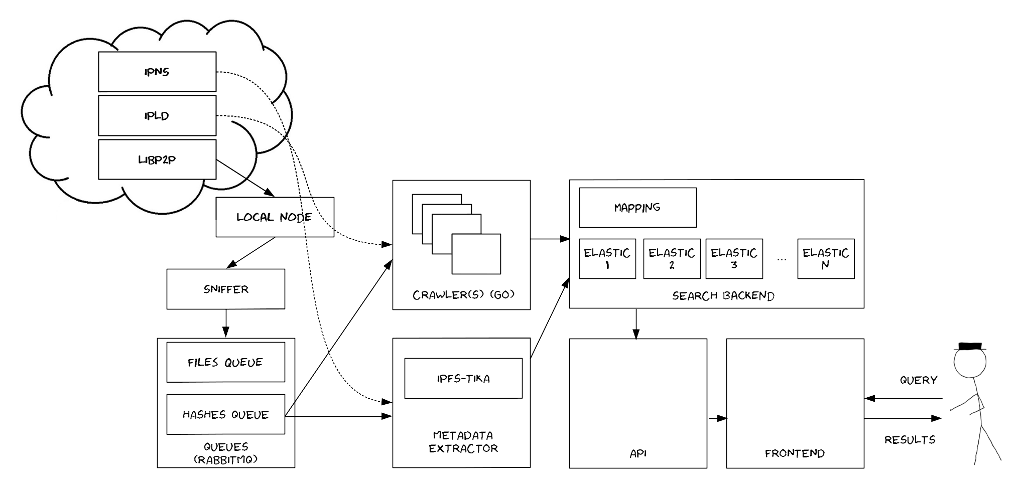
Search engine for the Interplanetary Filesystem. Sniffs the DHT gossip and indexes file and directory hashes.
Metadata and contents are extracted using ipfs-tika, searching is done using OpenSearch 7, queueing is done using RabbitMQ. The crawler is implemented in Go, the API and frontend are built using Node.js.
The ipfs-search command consists of two components: the crawler and the sniffer. The sniffer extracts hashes from the gossip between nodes. The crawler extracts data from the hashes and indexes them.
Docs: Documentation is hosted on here on Read the Docs, based on files contained in the GitHub docs folder. In addition, there’s extensive Go docs for the internal API as well as SwaggerHub OpenAPI documentation for the REST API.
Contact: Please find us on our Freenode/Riot/Matrix channel #ipfs-search:matrix.org.